Introduction: The Elephant in the Dark Room
Imagine a dark room where a group of people encounters an elephant for the first time. Each person touches a different part of the elephant—a trunk, a leg, an ear, a tusk—and describes what they feel.
- “The elephant is like a thick snake,” says the one holding the trunk.
- “No, it’s a sturdy pillar,” argues another, feeling the leg.
- “You’re both wrong. It’s a sharp spear!” insists the person touching the tusk.
Each person’s perspective is limited, yet each believes they hold the complete truth. This ancient tale from Rumi’s poetry is a powerful analogy for how biases shape our understanding—especially in data science.
Just like the people in the dark room, we often work with incomplete datasets but confidently draw conclusions as if we see the whole reality. However, bias is the unseen force that distorts our perception, leading to flawed insights. If we fail to recognize bias, we risk making decisions based on misleading or one-sided data.
In a world increasingly shaped by data, seeing the whole elephant isn’t just a philosophical ideal—it’s a practical necessity. This post explores the various types of bias that infiltrate data-driven decisions and provides strategies to mitigate them, and then I share you the lessons learned from my machine learning journey
1. Cognitive Biases: The Mental Shortcuts That Mislead Us
Cognitive biases are systematic thinking errors that occur because our brains try to simplify complex information. While these shortcuts can be helpful, they often lead to misinterpretations of data.
1.1. Confirmation Bias
Favoring information that aligns with preexisting beliefs while ignoring contradictory evidence. The risk of confirmation bias is high in scientific research, as researchers may focus on findings that support their hypothesis while overlooking side effects or conflicting data.
Example: A team of scientists selectively includes data points that support their hypothesis but dismisses outliers without investigation.
How to Fix It:
- Use blind analysis by having a separate team validate findings. As highlighted in Blind analysis: Hide results to seek the truth article.
- Encourage devil’s advocate discussions within teams.
- Rely on diverse data sources to avoid one-sided conclusions.
1.2. Availability Heuristic
Overestimating the importance of information that is easily recalled or recent.
Example: A health research team focuses on recent dietary trends as causes of diabetes, overlooking long-term factors like genetics, behaviors, socioeconomic conditions, and historical diets.
How to Fix It:
- Use historical data alongside recent insights.
- Apply weighted averaging to balance short-term and long-term trends.
- Use 5 Whys technique to explore the cause-and-effect relationships.
Cognitive biases affect how we interpret data, but biases don’t just exist in our minds—they also seep into the very datasets we collect and analyze.
2. Data Collection and Analysis Biases: When the Dataset Lies
Biases that occur during the process of gathering, selecting, cleaning or interpreting data. Data isn’t just what appears on a monitor—it should reflect multiple perspectives, not just the convenient or available ones.
A wise man once said: “The elephant is large because the Earth is vast.”
The elephant is large because the Earth is vast enough. (Image credit: Thomas Merkt)
Here, this reflects the idea that the dataset comes from a vast, complex world, complex world, and it’s crucial to ensure it represents a broad range of perspectives, not just the easy-to-access or available ones
2.1. Selection Bias
When the sample collected does not accurately represent the entire population.
Example: A political poll conducted only through online surveys may exclude older adults or lower-income individuals who have limited internet access. As a result, the findings may not accurately reflect the views of the entire population.
How to Fix It:
- Use stratified sampling to ensure diverse representation.
- Augment datasets with external sources, like parallel researches and competitor analysis.
2.2. Non-Response Bias
When individuals who do not respond to surveys differ significantly from those who do.
Example: A customer satisfaction survey mostly collects responses from highly engaged users, missing feedback from dissatisfied or inactive customers.
How to Fix It:
- Incentivize responses from all customer segments, not just engaged users.
- Use passive data collection (e.g., tracking behavior, not just surveys).
2.3. Measurement Bias
Errors in data collection due to faulty tools or methods.
Example: A weather prediction model trained on outdated sensor data will produce inaccurate forecasts.
How to Fix It:
- Regularly calibrate and audit data collection tools.
- Implement redundant systems to cross-check accuracy.
Even when data is collected properly, bias can still creep in through the way models and algorithms process it.
3. Algorithmic and Modeling Biases: When Machines Learn the Wrong Lessons
These biases arise during the development and application of machine learning models. Even with perfect data, flawed modeling choices can produce systematic errors.
3.1. Overfitting Bias
Creating a model that is too complex and learns noise instead of patterns.
Example: A model that performs well on training data but fails on unseen data.
How to Fix It:
- Use cross-validation to test generalizability.
- Apply regularization techniques to simplify models.
3.2. Underfitting Bias
Creating a model that is too simple to capture meaningful patterns.
Example: Using a linear regression model for a nonlinear problem.
How to Fix It:
- Test different model architectures and increase feature complexity where needed.
- Use exploratory data analysis (EDA) to determine the best approach.
Andrew Ng provides a comprehensive discussion of overfitting and underfitting in his Machine Learning course, It's highly recommend.
To better understand the impact of overfitting and underfitting on model performance, see the illustration below, which shows how bias and variance play a crucial role in achieving the right balance.
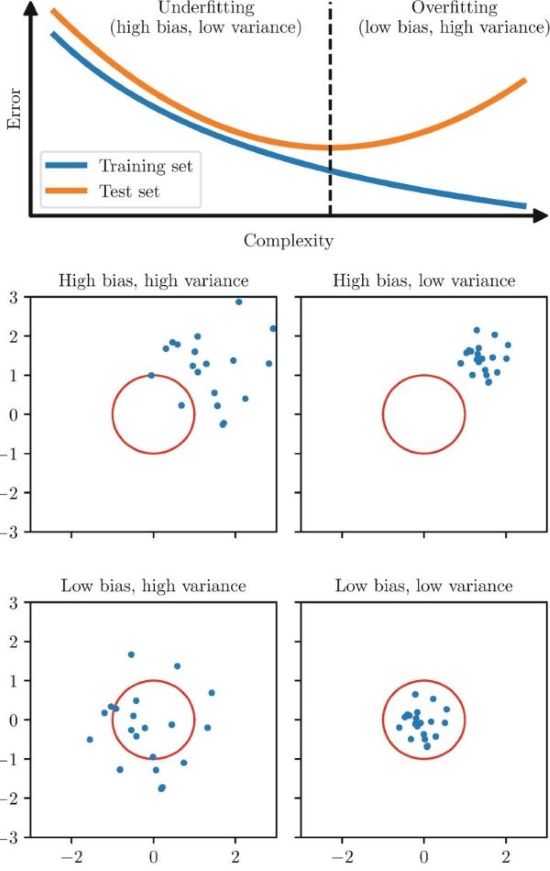
Illustration of Overfitting and Underfitting in relation to Bias and Variance
3.3. Algorithmic Bias
When an algorithm produces systematically biased results due to flawed assumptions or biased training data.
Example: A facial recognition system that misidentifies people of certain ethnic backgrounds more frequently because the training dataset was predominantly composed of lighter-skinned individuals.
How to Fix It:
- Ensure diverse and representative training datasets.
- Regularly audit model performance across different demographic groups.
- Use bias-correction techniques such as reweighting underrepresented samples.
Algorithms don’t exist in a vacuum—they are shaped by social and cultural forces, which can introduce hidden biases.
4. Social and Cultural Biases: The Invisible Forces at Play
Biases that stem from societal norms, cultural backgrounds, or group dynamics, influencing both data interpretation and decision-making.
4.1. Cultural Bias
Interpreting data through the lens of one’s own cultural background.
Example: A global company assumes customer behavior in Asia will mirror trends seen in North America.
How to Fix It:
- Conduct localized studies rather than assuming universality.
- Employ diverse teams to bring varied perspectives.
4.2. Authority Bias
Giving undue weight to the opinions of authority figures.
Example: A senior analyst’s flawed conclusion is accepted without question, despite data suggesting otherwise.
How to Fix It:
- Encourage a data-first culture where evidence outweights hierarchy.
- Use blind peer reviews to evaluate findings.
Lessons Learned: Overcoming the Bias in My Machine Learning Journey
From my experience, these actions have been instrumental in overcoming biases:
- Understand the origin of the data and the project's objectives: Make sure you have a clear understanding of where the data comes from and what problem you’re trying to solve.
- Communicate with stakeholders: Engage with people involved in data gathering, model execution, and outcome evaluation. Their feedback can provide invaluable insights into the domain and model performance.
- Define the scope of your project.
- Be cautious of sparse datasets: In cases with limited data, overfitting becomes a higher risk. Make sure your model is not learning noise rather than true patterns.
- For distributed datasets with many attributes: Be mindful of the risk of underfitting. When there are too many variables, your model might miss important patterns. Regularly assess the complexity of your models.
- Review global studies and successful methods: Look at similar studies and case examples worldwide to understand, for their cases, which methods worked well and why. This can offer valuable insights for your own work.
- Select appropriate evaluation metrics based on dataset and purpose: Choose metrics that truly reflect the model’s performance in the context of your problem, rather than relying on generic or superficial measures.
- Handling overfitting: If you're experiencing overfitting, consider increasing the size of the dataset or incorporating more attributes, if available.
- Handling underfitting: If your model is underfitting, explore increasing dataset size or adding relevant features. Avoid overly simplistic models that miss important trends.
- Fine-tune models based on observed metrics: Continuously refine and adjust your models, testing them against performance metrics to improve results over time.
- Experiment with different combinations of methods and models: The right approach often requires iteration. Don’t be afraid to try different combinations of algorithms and strategies to find the best fit.
- Be aware of overcomplicating models: Sometimes, the most complex models are not the best ones. Focus on finding the right balance between simplicity and complexity.For example, in some cases, although Neural Network approaches are computationally heavy, they may be too fragile and fail to perform better than simpler models.
- Choose the best models based on performance extremes: Select models that demonstrate strong performance on both the best and worst test cases. This "Best of the Best (BoB) and Worst of the Worst (WoW)" approach can help ensure robustness.
- Use Commissioning Quality Validation (CQV) method: Implement a CQV method throughout the project. Regularly test, validate, and refine your models to maintain their effectiveness and accuracy.
- Ensure model stability: Regularly test your model to confirm it is consistently performing well. If its performance fluctuates, reconsider your approach.
- Document dependencies: Always create a requirements file and store it with your project. Libraries and packages are updated frequently, and these updates can affect your model’s performance.
Final Thoughts: Seeing the Whole Elephant
Bias is inevitable, but awareness is the first step toward mitigation. Whether it’s cognitive shortcuts, flawed data collection, biased algorithms, or social influences, the key is to continuously question assumptions and broaden our perspectives.
Many researchers have explored these biases and the stories behind them—Rolf Dobelli, for instance, discusses several in The Art of Thinking Clearly.
Returning to the dark room, if each person had been illuminated by light, there would have been no conflict. In Rumi’s wisdom, light represents understanding and insight, and it is only through wisdom that we can navigate beyond our limited perspectives. Only by stepping beyond the narrow beam of our own flashlight can we begin to see the complete picture of the elephant.
One useful method that can help us adopt a more holistic view is the Six Thinking Hats by Dr. Edward de Bono. This technique encourages us to look at problems from multiple perspectives, helping us move past biases and get closer to the full picture.
Now over to you: How do you spot and mitigate bias in your work? Share your thoughts below!
Your Feedback Matters